
Il semblerait que l’écosystème de l'intelligence artificielle ait commis une erreur de calcul. Le secteur a longtemps considéré que le progrès passait nécessairement par la construction de systèmes de langage toujours plus vastes, capables de répondre à l’ensemble des usages imaginables. Ces grands modèles de langage se sont imposés comme la solution par défaut, concentrant investissements, ressources et attention médiatique. En réalité, la plupart des organisations n’ont pas besoin d’un couteau suisse lorsqu’elles recherchent un scalpel.
Un modèle de langage peut être défini comme un système entraîné à apprendre la structure statistique d'un texte. Lors de son entraînement, il analyse de grandes quantités de données et estime la probabilité d’apparition d’un mot en fonction de ceux qui le précèdent. Lorsqu’une phrase lui est soumise, le modèle s’appuie sur ces probabilités pour sélectionner le mot suivant le plus cohérent avec le contexte.
Un grand modèle de langage (Large Language Model, LLM) repose sur ce même principe, mais à une échelle bien plus large. Il intègre un nombre massif de paramètres, ce qui lui permet de couvrir un large éventail de sujets et de s’adapter à des usages très variés. Cette polyvalence a toutefois un coût. Entraîner et exploiter ces modèles exige une puissance de calcul importante ainsi que des infrastructures spécialisées.
A l’inverse, un petit modèle de langage (Small Language Model, SLM) applique le même principe, mais avec beaucoup moins de paramètres. Il est conçu pour répondre à des besoins précis ou à des fonctions bien définies, le rendant plus simple à déployer et à intégrer dans des systèmes existants. De plus, il peut fonctionner sur des infrastructures modestes.
Pendant longtemps, il a été admis que les progrès de l’intelligence artificielle passaient par des modèles toujours plus grands, gourmands en ressources de calcul et étroitement dépendants des fournisseurs de services cloud. Les SLM démontrent qu'il existe une autre voie. En plus d'être efficaces pour des tâches spécifiques et bien moins coûteux, ces modèles confèrent aux entreprises une plus grande autonomie, et un contrôle renforcé sur leurs données réduisant ainsi la dépendance onéreuse aux Hyperscalers.
Les grands modèles de langage
Les grands modèles de langage (LLM) sont le fruit de plusieurs décennies de progrès en traitement du langage naturel et en apprentissage automatique. Ils ont largement contribué à l’accélération technologique récente et sont désormais accessibles via des plateformes telles que ChatGPT d’OpenAI, Gemini de Google, Copilot de Microsoft ou Claude d’Anthropic.
Les LLM sont des systèmes d’apprentissage profond entraînés sur des volumes massifs de textes. Ils reposent sur une architecture appelée transformer, efficace pour analyser des séquences de mots et saisir des relations complexes sur de longues portions de texte. Lors de leur entraînement, ils sont exposés à d’immenses corpus (livres, articles, sites web, code informatique). Le modèle apprend en attribuant des probabilités aux enchaînements de mots et construit progressivement une compréhension statistique du langage. Lorsqu’une requête lui est soumise, il utilise cette connaissance pour prédire, mot après mot, la réponse la plus cohérente.
Ce qui distingue les LLM des modèles plus simples, c’est avant tout leur taille. Leurs paramètres internes se comptent en milliards, voire davantage. Cette ampleur leur permet de traiter des tâches nécessitant une connaissance générale étendue, une bonne compréhension du contexte ou une grande souplesse d’utilisation. Ils peuvent ainsi passer de la rédaction de contenus marketing à la synthèse de recherches, à l’écriture de code ou à des échanges conversationnels élaborés. Lorsqu’ils disposent de capacités dites agentiques, ils peuvent planifier et exécuter des actions avec un certain degré d’autonomie.
Cette puissance s’accompagne cependant de contraintes importantes. Les LLM exigent des ressources de calcul élevées et sont le plus souvent hébergés dans des environnements cloud. A grande échelle, leurs coûts d’exploitation augmentent rapidement. Leur polyvalence est réelle, mais l’infrastructure nécessaire pour la soutenir l’est tout autant.
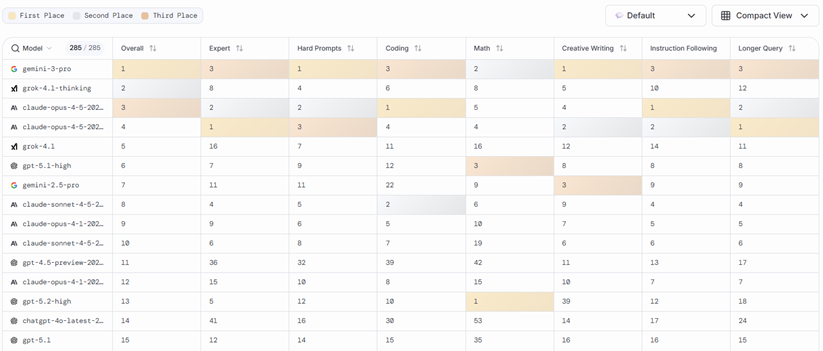
Source: LMArena
SLM: Faire plus avec moins
Les petits modèles de langage (SLM) reposent sur les mêmes principes prédictifs que leurs équivalents de grande taille, mais avec une fraction du nombre de paramètres, généralement moins de dix milliards. Cette réduction n’est pas une contrainte. En se concentrant sur des domaines plus restreints et des tâches clairement définies, les SLM deviennent plus légers, plus rapides et nettement plus simples à déployer.
Nombre d’entre eux peuvent fonctionner directement sur un appareil portable ou un serveur local, sans recourir aux lourdes infrastructures cloud qu’exigent les LLM. Cette exécution locale présente plusieurs avantages: des coûts réduits, des performances plus prévisibles et un meilleur contrôle des données, celles-ci ne quittant jamais l’environnement de l’utilisateur.
Leur efficacité les rend également très adaptables. Là où l’ajustement d’un LLM peut nécessiter plusieurs semaines et des ressources GPU considérables, un SLM peut souvent être affiné en quelques heures ou quelques jours, parfois sur un seul GPU haut de gamme.
Malgré leur taille plus modeste, les SLM modernes affichent des capacités remarquables. Des modèles tels que Gemma 2 de Google (2 milliards de paramètres), Phi-3 de Microsoft (3,8 milliards), Llama 3.1 de Meta (8 milliards), Nemotron Nano de NVIDIA (9 milliards) ou GPT-4o mini d’OpenAI (nombre de paramètres non communiqué) montrent que des architectures soigneusement optimisées peuvent rivaliser, voire surpasser, des systèmes bien plus volumineux sur des tâches spécialisées, de la génération de code aux tests de raisonnement.
Récemment, Microsoft a présenté Fara-7B, un petit modèle de langage expérimental conçu pour fonctionner directement sur l’ordinateur de l’utilisateur. Présenté comme le premier SLM agentique de l’entreprise pensé pour une exécution locale, il est capable d’interagir avec le système, notamment via la souris et le clavier. Avec sept milliards de paramètres, il reste très loin de l’échelle des anciens LLM comme GPT-3, qui en comptait 175 milliards. Selon Microsoft, Fara-7B «atteint des performances de pointe dans sa catégorie de taille et se montre compétitif face à des systèmes agentiques plus volumineux et plus gourmands en ressources, qui reposent sur l’orchestration de plusieurs grands modèles».
Dans de nombreux usages concrets, suivi d’instructions, utilisation d’outils ou tâches répétitives propres à un domaine, un modèle compact n’est pas seulement suffisant, mais même souvent préférable, en particulier lorsque les ressources de calcul sont limitées. Des systèmes comme les véhicules autonomes ou les satellites opèrent sous des contraintes strictes en matière de puissance de calcul, de consommation énergétique et de connectivité réseau. Dans ces environnements, les grands modèles sont tout simplement impraticables. Les SLM, en revanche, peuvent fonctionner directement à bord, permettant une prise de décision locale sans dépendre d’un accès permanent au cloud.
L’écart de coûts est tout aussi frappant. L’entraînement d’un modèle de la classe de GPT-4 est estimé à plus de 100 millions de dollars, tandis que Gemini Ultra pourrait atteindre 191 millions de dollars. Même l’adaptation de LLM existants à des usages spécifiques peut nécessiter plusieurs dizaines de milliers de dollars en temps GPU. À l’inverse, les SLM peuvent être entraînés et ajustés pour quelques milliers de dollars seulement. La différence est encore plus marquée à l’inférence. GPT-4 est facturé environ 0,03 dollar pour 1000 tokens (jetons) en entrée et 0,06 dollar pour 1000 tokens en sortie, soit un coût moyen d’environ 0,09 dollar par requête. Un SLM comme Mistral-7B, en comparaison, revient à environ 0,0001 dollar pour 1000 tokens en entrée et 0,0003 dollar pour 1000 tokens en sortie, soit 0,0004 dollar par requête. À grande échelle, sur des millions de requêtes, cet écart pèse lourdement sur les coûts d’exploitation, sans tenir compte des économies liées à l’hébergement.
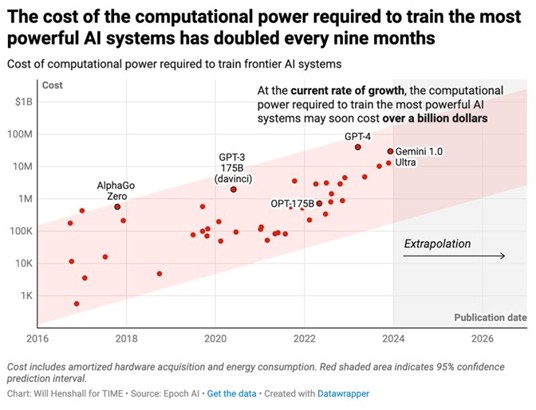
Source: Will Henshall for TIME, Epoch AI
Etablissements scolaires, organisations à but non lucratif et petites entreprises peuvent ainsi les déployer pour des tâches ciblées sans supporter des coûts prohibitifs. Des modèles comme Phi-3 de Microsoft sont déjà utilisés pour alimenter des plateformes d’information agricole en Inde, fournissant des conseils aux agriculteurs, y compris dans des régions où la connectivité est limitée.
Cette efficacité s’accompagne toutefois de compromis. Leur taille réduite limite leur capacité à généraliser sur des tâches mal définies ou inconnues. Ils peuvent montrer des faiblesses dès lors qu’un problème exige une connaissance très large ou un raisonnement en plusieurs étapes, ce qui se reflète dans les résultats face à certains benchmarks. Les SLM peuvent également hériter de biais présents dans leurs données d’entraînement, y compris ceux transmis par des modèles plus grands. Enfin, comme tous les systèmes génératifs, ils peuvent produire des réponses formulées avec assurance mais factuellement incorrectes.
Conséquences pour les Hyperscalers: l’industrie de l’IA a misé sur le mauvais cheval
Les hyperscalers ont adopté une stratégie fondée sur l’échelle, partant du principe que des modèles toujours plus grands et une puissance de calcul toujours accrue détermineraient l’avantage de long terme. L’évolution des modèles emblématiques est venue conforter cette conviction. GPT-3, avec ses 175 milliards de paramètres, a été largement salué comme une percée en 2020. GPT-4, qui compterait près de 1800 milliards de paramètres, a encore relevé le niveau d’exigence. L’ensemble de l’écosystème s’est alors aligné sur cette trajectoire, investissant massivement et accélérant la construction d’infrastructures avant même d’avoir clairement identifié les besoins des usages réels.
D’après les estimations de McKinsey, les dépenses mondiales en infrastructures d’intelligence artificielle pourraient atteindre entre 3700 et 7900 milliards de dollars d’ici 2030. Au deuxième trimestre 2025, 98% des 82 milliards de dollars investis dans ce domaine ont été consacrés aux serveurs, dont 91,8% à des systèmes accélérés par GPU ou XPU. Les Hyperscalers et les acteurs du cloud ont représenté 86,7% de ces dépenses, soit environ 71 milliards de dollars sur un seul trimestre. Le capital s’est ainsi concentré sur des équipements extrêmement spécialisés et très énergivores, conçus pour entraîner et exploiter des modèles de très grande taille. Or, dans la majorité des cas, les applications en entreprise ne requièrent pas un tel niveau de capacité.
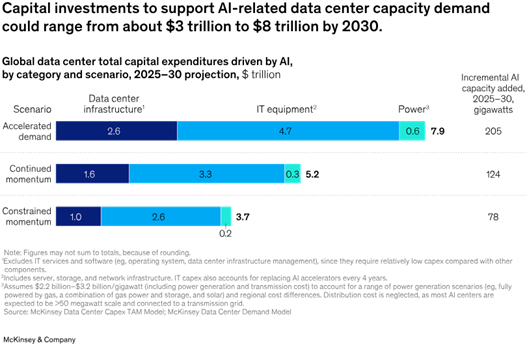
Source: McKinsey & Company
Selon un article récent de Nvidia Research, voix loin d'être marginale dans le domaine de l'IA, «les petits modèles de langage représentent l'avenir de l'IA agentique». Les systèmes multi-agents démontrent qu'entre 40% et 70% des tâches quotidiennes peuvent être exécutées par des SLM sans perte d'efficacité. Selon les termes de Nvidia, «les petits modèles de langage sont suffisamment puissants, intrinsèquement mieux adaptés et nécessairement plus économiques pour de nombreuses sollicitations au sein des systèmes agentiques». Aujourd'hui, nombre d'applications basées sur des agents s'appuient sur des modèles largement surdimensionnés par rapport aux tâches à accomplir. Remplacer ces systèmes lourds par des SLM peut réduire les coûts jusqu'à vingt fois tout en préservant les performances dans la plupart des flux de travail.
Malgré leurs atouts, l'adoption des SLM progresse plus lentement que prévu. Nvidia identifie plusieurs raisons structurelles. Des années d'investissements massifs ont enfermé les organisations dans des infrastructures centrées sur les LLM, et les référentiels du secteur continuent de valoriser l'échelle, renforçant l'idée que plus grand signifie meilleur. Ainsi, bien que les SLM soient souvent plus pratiques et économiques, l'écosystème reste façonné par de grands systèmes basés sur le cloud.
Conclusion
L'article de Nvidia ne se limite pas au constat et trace une voie à suivre. Il préconise une architecture hybride. Les SLM prennent en charge les charges de travail ciblées et répétitives, tandis que les LLM sont réservés aux tâches exigeant véritablement un raisonnement large ou des interactions ouvertes. Le choix entre petits et grands modèles ne porte pas sur lequel est meilleur, mais sur lequel est approprié.