
L’un des tropes culturels les plus efficaces est celui du narrateur peu fiable. Dans des romans tels que «Le Meurtre de Roger Ackroyd» d’Agatha Christie ou des films comme «Usual Suspects» de Bryan Singer, le narrateur ou le personnage à travers les yeux duquel nous suivons l’histoire est un observateur peu fiable, ce qui entraîne une instabilité dans notre compréhension des événements ainsi que des rebondissements inattendus. Sur les marchés financiers, les investisseurs en sont venus à se fier à des données mensuelles ou trimestrielles qui les aident à appréhender l’environnement macroéconomique. Or, ces données font l’objet de révisions de plus en plus fréquentes, parfois substantielles, au cours des mois et des années qui suivent leur publication. Pourquoi les statistiques économiques sont-elles devenues si peu fiables? Et qu’est-ce que cela signifie pour l’économie et les marchés financiers?
Tout d’abord, il convient de noter que, si les statistiques économiques américaines ne sont pas devenues inutilisables, elles sont toutefois plus fragiles, plus sujettes à révision et plus vulnérables à des interprétations erronées en temps réel. Cela remet en question l’habitude qu’ont les investisseurs de bouger leurs portefeuilles sur la base des premières publications de données: ils peuvent se ruer sur des actions sensibles au cycle économique en raison de données d’activité solides, pour finalement constater que cette vigueur a été révisée à la baisse. Cela signifie que les actions qu’ils achètent pourraient ne jamais connaître la hausse de chiffre d’affaires espérée. Cela signifie également que les investisseurs devraient appliquer des intervalles de confiance plus larges aux publications à haute fréquence, se fier moins aux chiffres phares isolés et accorder une plus grande attention aux révisions, aux divergences entre les enquêtes et à la manière selon laquelle les données sont récoltées.
Au travail ou au chômage?
Le marché du travail est l’exemple le plus flagrant de ce manque de fiabilité. Cette perception a même poussé le président Trump à limoger Erika McEntarfer, la directrice du Bureau des statistiques du travail (BLS), en août dernier, l’accusant d’avoir manipulé les chiffres de l’emploi pour «nuire à l’image des républicains, et à la MIENNE». Cette accusation était infondée, mais le problème sous-jacent est bien réel. Les premières publications font l’objet de révisions massives et la divergence entre les composantes «entreprises» et «ménages» des rapports sur l’emploi du BLS est devenue plus difficile à ignorer.
L’enquête auprès des entreprises mesure l’emploi en s’appuyant sur les registres de paie d’environ 119’000 entreprises et organismes publics couvrant quelque 622’000 lieux de travail, tandis que l’enquête auprès des ménages recense les personnes ayant un emploi, au chômage ou inactives dans environ 60’000 ménages. Cette distinction est importante car les personnes occupant plusieurs emplois sont comptées plusieurs fois dans les registres de paie, tandis que le travail indépendant, l’agriculture et le travail informel sont mieux pris en compte dans l’enquête auprès des ménages. Les récentes hausses de l’emploi enregistrées dans les registres de paie ont donc semblé plus fortes que certaines mesures de l’emploi issues de l’enquête auprès des ménages, ce qui crée le risque que les investisseurs surestiment l’ampleur et la résilience de la demande de main-d’œuvre.
L’ampleur des révisions s’est accrue ces dernières années. Par exemple, en février 2026, la révision de référence finale du BLS a réduit le niveau des effectifs salariaux corrigé des variations saisonnières de mars 2025 de -898’000, soit -0,6%, ce qui est énorme. Le BLS a attribué une partie de la surestimation initiale aux erreurs de réponse et à l’absence de réponses, les registres ultérieurs de l’assurance chômage ayant révélé des tendances de l’emploi plus faibles parmi les entreprises n’ayant pas répondu que parmi celles ayant répondu. Cela revêt une importance considérable pour les investisseurs: cela signifie que la première estimation n’était pas simplement imprécise, mais aussi trop optimiste dans son orientation.
Un autre problème réside dans la dispersion sectorielle, qui n’est pas prise en compte par les chiffres globaux. Selon l’économiste canadien David Rosenberg, l’emploi US est en plein essor dans les secteurs de la santé et de l’éducation, avec une hausse de 2,5% en glissement annuel. Mais ces secteurs ne représentent que 18% de l’emploi – le reste a connu une baisse de l’emploi au cours des douze derniers mois.
Le modèle «naissances-décès» (qui tente de corriger la sous-estimation des emplois créés par les start-ups et la surestimation des emplois perdus lorsque des entreprises font faillite et cessent de déclarer leurs données) constitue une autre vulnérabilité, car il repose sur des inférences fondées sur des tendances historiques qui ne sont plus pertinentes dans l’économie post-pandémique actuelle. En effet, le BLS a implicitement reconnu ce risque et a modifié son modèle à compter de janvier 2026 afin d’intégrer chaque mois les informations issues de l’échantillon actuel.
Enfin, les commentateurs ignorent souvent les tendances démographiques lorsqu’ils évoquent le marché de l’emploi. Le dernier taux de fécondité américain s’élève à 1,6 enfant par femme, ce qui est bien inférieur au taux de 2,1 nécessaire pour maintenir la population à un niveau stable. De plus, le taux de fécondité est resté inférieur à 2,1 de 1973 à la fin des années 1980, avant de remonter à un niveau proche du seuil de renouvellement jusqu’en 2008, date depuis laquelle il n’a cessé de baisser. Cela signifie que les États-Unis ont dû compter sur l’immigration pour assurer la croissance du marché du travail pendant environ 50 ans. Ce système a bien fonctionné jusqu’en 2025, date à laquelle l’immigration est tombée «à un niveau proche de zéro, voire négatif… pour la première fois depuis au moins un demi-siècle», selon la Brookings Institution. Le succès de la politique de répression de l’immigration menée par le président Trump signifie que l’offre de main-d’œuvre stagne ou diminue et que la croissance nulle des emplois non agricoles ne doit plus être considérée comme une déception.
Heureux ou tristes?
Les données sur la confiance des consommateurs constituent un deuxième exemple de manque de fiabilité, même si le problème tient ici moins à une défaillance statistique qu’à une question d’interprétation. Ces derniers trimestres, les enquêtes de l’Université du Michigan et du Conference Board ont présenté des résultats divergents (voir le graphique ci-dessous) car elles mesurent différentes dimensions de la psychologie des ménages. L’indice préliminaire de confiance du Michigan pour juin 2026 s’est établi à 48,9, en hausse par rapport aux 44,8 de mai, mais toujours bien en deçà des niveaux enregistrés il y a un an, et a été fortement influencé par les inquiétudes liées à l’inflation depuis le début de la pandémie. En revanche, l’indice de confiance des consommateurs du Conference Board pour mai 2026 n’a pas connu de baisse aussi marquée, soutenu par une perception toujours optimiste des conditions du marché du travail. L’indice du Michigan est donc plus utile pour évaluer la pression inflationniste et la propension à effectuer des dépenses importantes, tandis que celui du Conference Board est plus étroitement lié à la sécurité de l’emploi et aux anticipations de revenus.
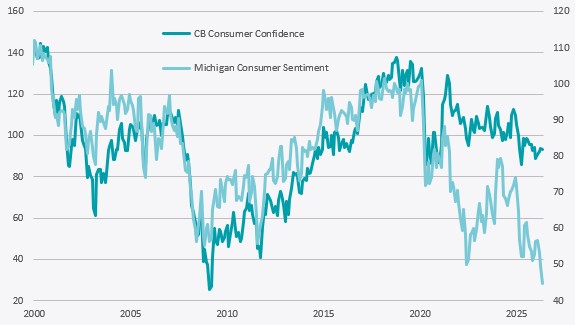
Le risque est que les investisseurs considèrent l’une de ces enquêtes comme «erronée», alors qu’en réalité, elles répondent à des questions différentes. Un ménage peut se sentir financièrement moins à l’aise en raison de la hausse des prix, tout en continuant de croire que des emplois restent disponibles. Cette combinaison est tout à fait plausible dans une phase d’expansion en fin de cycle, sensible à l’inflation.
La polarisation politique complique encore davantage l’interprétation (le Michigan recueille des données mensuelles sur l’affiliation politique depuis 2017). Par exemple, après l’élection de Trump en 2024, l’indice des anticipations de novembre pour les républicains a bondi de 27,8 points tandis que celui des démocrates a chuté de -17,7 points. Les méthodes utilisées pour collecter les données d’enquête ont également leur importance. En 2024, après sept ans de tests parallèles, l’université du Michigan est passée des entretiens par téléphone mobile avec numérotation aléatoire aux enquêtes en ligne, augmentant ainsi l’échantillon mensuel d’environ 600 à 900–1000 personnes. Si cela peut améliorer la représentativité du sondage, cela crée également une rupture dans la méthode de collecte que les investisseurs ne devraient pas ignorer.
Un problème plus large
Le problème dépasse le cadre de l’emploi et du moral des consommateurs. La mesure de l’inflation est devenue plus incertaine, car les estimations en temps réel sont sujettes à des révisions, à des imputations et à une complexité méthodologique. Les estimations de l’inflation sous-jacente des dépenses de consommation personnelles (PCE) sont fréquemment révisées, le plus souvent de manière modérée. Mais selon la Fed de New York, ces révisions présentent des «queues épaisses» statistiques. Dans 15% des cas, les révisions historiques ont dépassé un point de pourcentage et certains cas extrêmes ont même atteint jusqu’à six points de pourcentage. Il s’agit malheureusement peut-être d’un problème structurel: les données du PCE reposent sur des contributions provenant de sources commerciales et administratives, dont beaucoup arrivent avec un décalage ou font l’objet de révisions parfois très importantes.
L’indice des prix à la consommation (IPC) a également fait l’objet de critiques concernant l’opacité des hypothèses relatives aux composantes liées au logement, telles que le loyer équivalent des propriétaires, où les observations manquantes peuvent être imputées ou supposées inchangées. Cela a son importance car la composante «logement» de l’IPC représente environ 35% du panier total. Si elle est mal mesurée, le chiffre global risque alors de s’écarter des tendances réelles de l’inflation des prix.
D’autres indicateurs sont également sujets à un manque de fiabilité. Les données JOLTS sur les offres d’emploi et les salaires semblent désormais présenter des intervalles de confiance statistiques plus larges, les estimations suggérant que les erreurs-types des principales enquêtes ont augmenté d’environ 26% par rapport aux normes d’avant la pandémie.
Le PIB est structurellement plus robuste, mais reste soumis à des révisions substantielles à mesure que des données sources plus complètes deviennent disponibles. Les révisions les plus importantes surviennent généralement lors de crises économiques: en 2008, pendant la Grande Récession, la croissance américaine avait initialement été estimée à 1,3%, avant d’être révisée à la baisse à seulement 0,1%; quant à l’impact de la pandémie de 2020, il avait d’abord été estimé à une récession de -3,5%, depuis lors révisé à -2,2%.
En outre, les perturbations opérationnelles, notamment les licenciements dans les bureaux statistiques décidés en 2025 par le Department of Government Efficiency d’Elon Musk, la fermeture des services publics liée au dépassement du plafond de la dette en en fin d’année dernière, ont également entraîné des lacunes flagrantes dans les données, des retards de publication et des distorsions dans la continuité des séries chronologiques. Les autres causes courantes sont la baisse des taux de réponse aux enquêtes, le recours accru à l’imputation et à la modélisation, les contraintes budgétaires, les perturbations opérationnelles, les risques de politisation et la transition structurelle vers une économie plus numérique, axée sur les services et fragmentée.
Les bureaux statistiques commencent à s’attaquer au problème du manque de fiabilité
Les mesures prises vont dans la bonne direction, mais ne suffisent pas encore à éliminer le problème. Le Bureau of Labor Statistics et le Census Bureau s’orientent vers des systèmes de réponse autonome sur Internet, notamment une option de réponse en ligne pour l’enquête auprès des ménages prévue en 2027, bien que des contraintes budgétaires puissent retarder la mise en œuvre complète.
Les organismes recourent également davantage aux registres administratifs, aux prix extraits du Web et aux ensembles de données du secteur privé, tout en augmentant la taille des échantillons, en prolongeant les périodes de collecte et en expérimentant la collecte en mode mixte. Le Census Bureau poursuit une modernisation informatique plus large grâce à des plateformes de données d’entreprise et à des systèmes de collecte intégrés. Ces réformes devraient aider, mais elles ne constituent pas une solution miracle. La collecte numérique peut améliorer la couverture et réduire les coûts, mais elle peut également introduire de nouveaux biais de sélection si elle n’est pas gérée avec soin.
Conclusion
Le caractère peu fiable des données macroéconomiques américaines devrait persister jusqu’à l’émergence de nouveaux outils permettant d’améliorer la qualité des données. L’un de ces outils pourrait être fourni par Truflation, un flux de données privé et décentralisé qui recense 18 millions de points de prix répartis sur douze catégories de dépenses des ménages, fournis par plus de 30 fournisseurs de données tiers. Il met à jour quotidiennement les estimations de l’IPC et du PCE, c’est-à-dire jusqu’à un mois et demi avant la publication des données officielles. Vendredi dernier, Truflation estimait l’IPC américain à 1,9% en glissement annuel, contre 4,2% selon le dernier rapport gouvernemental, et l’indice PCE global à 2,5%, contre 4,1%. Mais tant que de tels outils n’auront pas été développés et reconnus comme un complément ou un substitut aux séries de données actuelles, les investisseurs devront apprendre à prendre les publications de données macroéconomiques avec des pincettes. Cela implique qu’une réflexion plus poussée et critique devra se substituer à l’observation des fausses pistes dessinés par des narrateurs économiques peu fiables.